📊 Full opportunity report: Mac vs GPU Tower for Local LLMs: The Heat-and-Noise Tradeoff on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
This article compares Mac Silicon and GPU tower setups for running local large language models, focusing on heat, noise, and performance tradeoffs. The choice depends on model size and workload needs.
Recent discussions highlight a fundamental tradeoff in choosing between Mac Silicon and GPU towers for local large language model inference, focusing on heat, noise, and capacity. Mac devices are near-silent and power-efficient but limited in maximum model size, while GPU towers offer higher throughput at the cost of heat and noise.
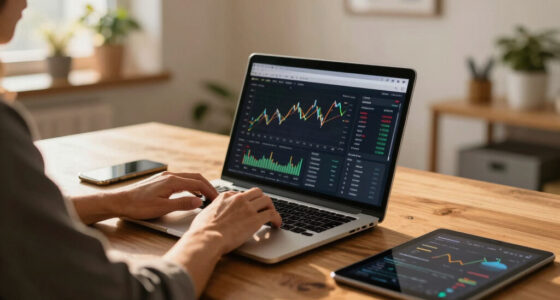
The core difference lies in architecture: GPU towers prioritize memory bandwidth, enabling faster inference on models that fit within VRAM, with RTX 5090 cards delivering approximately 1,792 GB/s. However, they consume significant power—over 575W per GPU—and generate substantial heat, requiring extensive thermal management. In contrast, Apple Silicon chips like the M3 Ultra optimize memory capacity, offering up to 512GB of unified memory, allowing the loading of large models such as 70B parameters that cannot fit into typical GPU VRAM. These Macs operate quietly and consume far less power, making them ideal for continuous, low-noise operation but with slower inference speeds. The choice hinges on whether the workload fits within VRAM for maximum speed or requires larger capacity for bigger models.Mac vs GPU tower
for local LLMs.
What if you sidestep the heat entirely with a different kind of machine? A tower is a high-bandwidth furnace you spend five levers quieting. Apple Silicon is near-silent by design — but asks for different tradeoffs. Match your priority in Part 2.
Put the loud, hot machine where its noise doesn’t matter, and the quiet one where you do. SSH into the tower when you need raw power; let the Mac handle everything else, silently.
Impact of Heat and Noise on Local AI Infrastructure
This comparison impacts users' decisions based on their model size requirements, operational environment, and workload priorities. GPU towers excel in raw throughput and flexibility for models within VRAM limits, suitable for latency-sensitive applications. Conversely, Macs offer a silent, energy-efficient solution for larger models that exceed GPU VRAM, ideal for continuous, low-noise operation. Understanding these tradeoffs informs choices for deploying local AI systems, especially in office or home settings where noise and heat are concerns.high performance GPU tower for AI inference
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Architectural Foundations of Heat and Capacity Differences
The debate stems from fundamental architectural differences: GPU towers emphasize high bandwidth for rapid data transfer, with consumer GPUs like the RTX 5090 providing nearly 1,800 GB/s, enabling faster inference on models that fit in VRAM. However, VRAM is limited to 24–32GB per card, and multiple GPUs do not pool memory, restricting model size. Apple Silicon chips utilize a unified memory architecture, sharing up to 512GB across CPU, GPU, and Neural Engine, allowing larger models to be loaded at the expense of slower read speeds. These design choices directly influence heat output and power consumption, with GPU towers acting as heat-generating high-power devices, while Macs are optimized for low heat and noise."The GPU tower is a space heater you manage, drawing hundreds of watts and producing significant heat, while Apple Silicon is near-silent and cool by design."
— Thorsten Meyer

WYGCH Korean Language White Ultra Thin Silicone Full Size Wireless Numeric Keyboard Cover Skin for Mac 2017 Magic Keyboard with Numeric Keypad MQ052LL/A A1843 US Layout
Compatible ONLY with full size Magic Keyboard with Numeric Keypad MQ052LL/A and A1843 ( Released 2017)US Layout
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Aspects of Performance and Scalability
It remains unclear how upcoming GPU architectures or future Mac Silicon generations will shift these tradeoffs, especially regarding multi-GPU scaling and software ecosystem maturity. The long-term upgradeability of Macs for AI workloads is also uncertain, as they are fixed at purchase, unlike GPU towers which can be expanded and upgraded.
Thermaltake View 600 TG; Full Tower; 420mm Radiator Support; 480mm GPU Clearance; Hidden Connector Support; Rotatable PCIe Slots; 220mm PSU Clearance; Black; CA-11H-00F1WN-00
【Premier View】Create a centerpiece to display thanks to the triple tempered glass front panel that’s reminiscent of a...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Future Developments in Hardware and Ecosystem Support
Next steps include observing how new GPU models improve bandwidth and power efficiency, and whether Apple Silicon will enhance its AI ecosystem to better support larger models or multi-device setups. Software improvements and ecosystem maturity will also influence the practical viability of each approach for different workloads.
NOVATECH AI Workstation Desktop PC – Intel Core i9-14900K, Liquid Cooling – Machine Learning, Data Science, 3D Rendering, Video Editing, Simulation (RTX 5080 | 64GB RAM | 2TB)
Extreme AI & Machine Learning Performance Powered by the Intel Core i9-14900K and RTX 5080 with 16GB VRAM,...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can a Mac run large language models as effectively as a GPU tower?
Macs can run larger models that do not fit in GPU VRAM due to their high-capacity unified memory, but inference speeds will generally be slower compared to GPU towers optimized for bandwidth.
Is heat and noise a significant concern for GPU towers?
Yes, GPU towers generate substantial heat and noise, requiring active thermal management and noise mitigation efforts, especially in continuous operation scenarios.
Will future GPU or Mac Silicon upgrades change this tradeoff?
Potential hardware advancements could shift the balance, but current differences are primarily due to fundamental architectural choices. Ecosystem support and software optimization will also influence future performance.
Which setup is better for real-time AI inference?
For latency-sensitive, high-throughput tasks within VRAM limits, GPU towers are preferable. For larger models or quieter operation, Macs offer a compelling alternative despite slower speeds.
How does power consumption compare between the two options?
GPU towers consume hundreds of watts—often over 800W for multi-GPU setups—while Macs typically use a fraction of that power, making them more energy-efficient for continuous operation.
Source: ThorstenMeyerAI.com