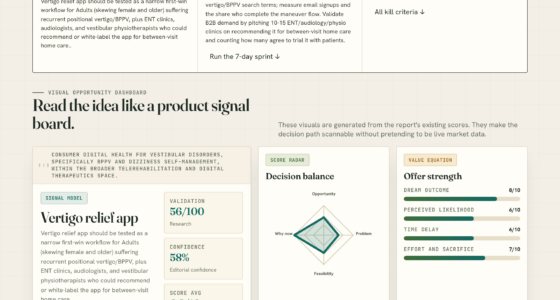
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The AI industry is shifting from compute to data as the primary bottleneck. Data fencing, licensing, and verification are now crucial, favoring established players and complicating access for startups. The scarcity of high-quality, verified data is driving new industry tactics.
In 2026, the AI industry has seen a decisive shift: data scarcity and fencing have become the new chokepoints, replacing compute as the primary barrier to model development. This change is driven by legal, economic, and strategic factors, making high-quality, verified data increasingly expensive and hard to access, which impacts both industry giants and startups. See how AI-enabled cyber threats are evolving.
Industry estimates indicate that the public internet holds roughly 300 trillion tokens of high-quality text, but this resource is nearing exhaustion. By 2028, publicly available data may be fully utilized, with synthetic data unable to fully replace the need for real, verified human-generated information. Major legal cases, such as Anthropic’s $1.5 billion settlement over copyright infringement, mark the end of free web scraping for training data, shifting toward a market-based licensing regime. Learn about AI and legal challenges. This trend favors large companies with deep pockets, creating barriers for smaller entrants.
Simultaneously, the industry has moved from simple data scraping to acquiring specialized, expert-authored data. Companies now require domain experts—lawyers, scientists, medical professionals—to generate high-value training datasets. This shift has led to increased data fencing, with firms like Meta investing heavily in controlling access to expert data, and rival companies forming alliances to secure proprietary information. The most valuable data is now that which cannot be bought but is generated through unique, often secretive, efforts—such as Ukraine’s Avengers Labs providing combat drone footage for exclusive training. Explore the risks of AI data fencing.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Implications of Data Fencing on AI Development
This shift matters because it concentrates AI development within a few well-funded firms capable of securing and licensing high-value data. Smaller startups face higher barriers to entry, risking industry consolidation and reduced competition. The move toward proprietary data pools also raises questions about transparency, fairness, and the future accessibility of AI technology.
high-quality AI training data datasets
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Changes Reshaping Data Access
Historically, AI training relied on freely available web data, but legal actions in 2026, including Anthropic’s landmark copyright settlement, have established that scraping copyrighted material without licensing is no longer permissible. Major publishers and legal entities are now moving toward licensing agreements, creating a market for data that previously was free. Meanwhile, the industry’s focus has shifted from open web crawling to securing specialized, verified datasets, often involving expensive expert input. This evolution reflects broader legal, economic, and strategic trends shaping AI’s future landscape.
“The cumulative sum of human knowledge is essentially exhausted for training AI models.”
— Elon Musk
expert-authored data for AI training
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Questions About Data Scarcity and Industry Impact
It remains unclear how quickly data fencing will fully restrict access for smaller players, and whether synthetic data can sufficiently compensate for the loss of real human-generated data. Additionally, the long-term effects of proprietary data pools on innovation and competition are still uncertain, as legal and market dynamics continue to evolve.

Understanding Open Source and Free Software Licensing
Used Book in Good Condition
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Future Industry Responses to Data Fencing and Scarcity
Expect ongoing legal battles over data licensing and more companies investing in proprietary, high-quality datasets. Smaller firms may seek alternative strategies, such as developing synthetic data or forming exclusive partnerships. Monitoring how legal rulings and market structures develop will be key to understanding AI’s future landscape.

Synthetic Data Generation: A Beginner’s Guide
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is data becoming more expensive for AI training?
Legal actions, copyright enforcement, and the end of free web scraping have made high-quality, verified data more costly and harder to access, shifting the industry toward licensing and proprietary datasets.
What is the significance of the Anthropic settlement?
The $1.5 billion settlement marks a legal turning point, signaling that free scraping of copyrighted materials is no longer permissible and establishing a precedent for market-based data licensing.
How does data fencing affect startups in AI?
Data fencing and licensing create high barriers for startups lacking the resources to acquire or generate proprietary data, favoring established firms with deep financial backing.
Can synthetic data replace real human-generated data?
Synthetic data is increasingly used, but it carries risks of errors and model collapse, especially in complex domains where verification is difficult, making real data still essential.
What types of data are now most valuable for AI training?
The most valuable data is that which is unique and hard to replicate, such as expert-authored, verified, and proprietary datasets that cannot be bought or scraped freely.
Source: ThorstenMeyerAI.com